
Machine Learning’s Sirens: Deep Dreaming and Open Sourcing Censorship
Reading Brand’s 1987 account of artificial intelligence research at the MIT Media Lab, I was struck by its laughably ambitious projects: “We want to be able to type in a Shakespeare play and have the computer act it out for us automatically” (Zeltzer, Brand 112). It’s a goal about as fantastically distant from the current state of machine learning as Star Trek’s Holodeck is from our modern virtual reality technologies.
However, it does raise an important question: what happened to the creative aspirations of artificial intelligence and machine learning? In the intervening three decades since Brand’s account of MIT’s Vivarium, research in machine learning has been focalized in what Jaron Lanier calls ‘Siren Servers’:
“[the gather] data from the network, often without having to pay for it. The data is analyzed using the most powerful available computers, run by the very best available technical people. The results of the analysis are kept secret, but are used to manipulate the rest of the world to advantage” (Lanier 55)
In this probe, I’ll be (cursorily) exploring how these Siren Servers are entangled with modern research in machine learning.
Machine learning represents an important kind of tool-making, particularly, because of the ambition to “fashion puppets that pull their own strings” (in the words of Ann Marion, quoted in Brand 97). The field, a discipline of Computer Science encompasses handwriting recognition, spam filtering, facial recognition, and hundreds of other applications. Recently, Concordia’s own machine learning lab has done work in detecting counterfeit coins. In summary, the field is concerned with “the studying and constructing algorithms that can learn forms and make predictions about data” (Wikipedia: Machine learning).
One point of entry is Google’s recent release (open-sourcing) of its machine learning library Tensorflow. I speculate that Google open sourced their machine learning library to keep pace with the already open machine learning library Torch. By opening the source of Tensorflow, the library can now benefit from the collaborative improvement and testing that open software encourages (Torch has been open for years).
If the locus of research in machine learning is in the development of these tools (Google’s Tensorflow and Torch), then we have to ask how these corporations determine the affordance of these tools. As Hassan noted, for these corporations,
“[t]he dream is not of the enrichment of cultures and the diversity of human experience, but a much more prosaic reality of markets, consumers, profits, regularity and standardization – the basic elements of a capitalist economy” (98).
Superficially, it seems like a boon from the great Googly-god. To compete with another library, Google’s hand was forced open, and now the commons has access to more toys for the virtual-class to play with. Let’s investigate further, following Sterne, and examine how this technology is situated socially.
This release comes on the heels of September’s Deep Dream excitement, when Google released a part of their machine-learning toolkit. The tool creates psychedelic images based on training images of natural phenomena (the inciting post and further explanation can be found here).
Deep Dream sparked a massive interest in machine learning and visual processing: tutorials on setting up the tools were popping up on hacker news and reddit, twitter was flush with deep dream images, and some artists even managed to apply it to video:
The banner image of this post is an image of TNG’s Lieutenant Riker entering the Holodeck I took from the star-trek wiki memory-alpha and ran through the online deep dream generator.
There’s much to be said about how this tool functions as a kind of cultural technique, particularly in how it creates a set of new modes for exploring images and visual processing. Despite the gimmicky excitement around these advanced machine learning techniques producing funky images and videos, I’d like to offer a more cynical view: was Google marketing and testing the punchiest of its machine learning applications in an effort to stir public interest in its algorithms? Consider how Google framed the release of Tensorflow last week:
The answer is simpler than you might think: We believe that machine learning is a key ingredient to the innovative products and technologies of the future. […] Research in this area is global and growing fast, but lacks standard tools. […] we hope to create an open standard for exchanging research ideas and putting machine learning in products. Google engineers really do use TensorFlow in user-facing products and services, and our research group intends to share TensorFlow implementations along side many of our research publications. [source]
Even Wired (that beacon of techno-determinism lambasted in Babrook and Cameron’s Californian Ideology) reported on Google’s release of this library with concern:
In the article, Biedwald points out, you can’t necessarily get access to the same data if you’re an academic. “It’s kinda hard for academics and startups to do really meaningful machine learning work,” he says, “because they don’t have access to the same kind of datasets that a Google or an Apple would have”. [Wired]
This is the newest manifestation of information asymmetry that Barbrook warned of:
“Alongside the ever-widening social divisions, another apartheid between the ‘information-rich’ and the ‘information-poor’ is being created. Yet the calls for the telcos to be forced to provide universal access to the information superstructure for all citizens are denounced in Wired magazine as being inimical to progress. Whose progress?” (5)
Progress for the Siren Servers.
After all, they are “characterized by narciccism, hyperamplified risk aversion, and extreme information asymmetry” (Lanier 54). Google and Facebook are in spectactular positition to exploit this information asymmetry: they own the largest collections of user data in the world.
Andrew Ng (currently employed by Baidu, the Chinese Web services company) explains how this asymmetry plays out in a machine learning context:
I think AI is akin to building a rocket ship. You need a huge engine and a lot of fuel. If you have a large engine and a tiny amount of fuel, you won’t make it to orbit. If you have a tiny engine and a ton of fuel, you can’t even lift off. To build a rocket you need a huge engine and a lot of fuel.
The analogy to deep learning [one of the key processes in creating artificial intelligence] is that the rocket engine is the deep learning models and the fuel is the huge amounts of data we can feed to these algorithms. [Wired]
Google is offers the ship, not the fuel.
Stewart Brand described (156-157) Negroponte’s offer to corporations that wanted to participate in the Media Lab: if you make the work here proprietary and hidden, we won’t let you see what else is going on. Now that this research is happening outside of academia, on the terms of these Siren servers, there’s a fundamentally distinct offer at hand: We’ll let you participate in the development of our tools for free. You get access to our tools and help us improve them, but we won’t let you see the data we collect, nor will we tell you how we’re using the tools you help us develop.
Machine learning’s political implications are not restricted to the those who use and develop its libraries. Consider Facebook in this context of data-collection as a “channel[s] much of the productivity of ordinary people into an informal economy of barter and reputation, while concentrating the extracted old-fashioned wealth for themselves.”(Lanier 57)
Every time I participate on Facebook, I am labouring for them. Facebook’s business model is dependent on its users providing free this free labour. The data it collects from its users is quantified by machine learning, and monetized.
“We also must recognize the potentiality of hypermedia can never be solely realised through market forces.” (Barbrook 7)
I’d like to direct the discussion of machine learning to a more sinister application: censorship. Remember Barbook’s description of the techno-utopia ambition to create an “electronic agora – in which everyone would be able to express their opinions without fear of censorship” (Barbrook 1).
It’s worth noting here that last month, an article critical of Facebook in relation to an EU privacy judgement could not be posted to Facebook: it considered it spam.
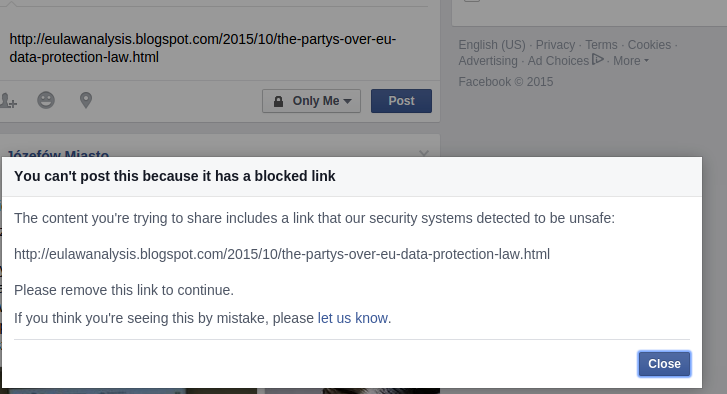
source: user mnx on hacker news https://news.ycombinator.com/item?id=10385670
A user (ostensibly speaking for Facebook) on hacker news replied:
If we really wanted to censor this story wouldn’t we block all criticism of Facebook and not a pretty straightforward and well-reasoned analysis of Safe Harbor? [the name of the judgement]” [source]
Even if Facebook didn’t intentionally censor the post, what does it mean if they can’t reliably distinguish criticism from spam? What has changed if Facebook can use their own shortcomings in machine learning as an excuse for censorship? When you control the language, can’t you control how spam is defined?
After all, we have no idea how Facebook is using its machine learning internally to detect spam, nor do we have access to the data that it collects. We’re hidden from the algorithms that determine the content and form of our media. This is not a fair compromise.
This case is foregrounds the question: where do we draw the line between spam-filtering and censorship? More importantly, how must we change how think about censorship if the media we are exposed too is being determined by algorithms that we have no access to. Moreover, what’s the ethical cost of contributing to the tools that may be involved in this process?
As intriguing as it is to poach (to freely assemble, reassemble and appropriate) from these incredibly rich machine learning tools, any tool must take account of what it excludes. If that means these Siren Servers are beyond criticism, and we’re content to share and promote these tools (by sharing Deep Dream images, or whatever the next machine learning fad is churned out), then we’ll have failed.
We need to think critically about the ethical cost of using these tools and libraries? They are complicit in both the surveillance and exploitation of the information-ecology that they create (with and without our consent). They have a political valence.
“Once people can distribute as well as receive hypermedia, a flourishing of community media, niche markets and special interest groups will emerge. […] In order to realise the interests of all citizens, the ‘general will’ must be realised at least partially through public institutions.” (Barbrook 7)
How can we emancipate machine learning from market forces? How can we take up the lofty ambitions that this probe began with, of creating learning machines that encourage us to learn along with them?
Works Cited
Barbrook, Richard, and Andy Cameron. “The Californian Ideology.” Mute 3 (Autumn 1995).
Brand, Stewart. The Media Lab: Inventing the Future at MIT. New York: Viking Penguin, 1987. chapters 1, 6, 9, 13.
Hassan, Robert. “The MIT Media Lab: Techno Dream Factory or Alienation as A Way of Life?” Media Culture & Society 25 (2003): 87–106.
Lanier, Jaron. Who Owns the Future? New York: Simon and Schuster, 2014. Print.

I, for one, do not welcome our robot overlords.